Unlocking the Power of LLM: A Deep Dive into Langchain, PGVector, Embeddings, Ollama, and RetrievalQA
Are you ready to unlock the power of Language Model models (LLMs) and delve into the fascinating world of Langchain, PGVector, Embeddings, Ollama, and RetrievalQA 🤯

Created by Dalle-3
Introduction:
Large Language Models (LLMs) such as OpenAI's ChatGPT, Llama 2 and Mistral are revolutionising the field of artificial intelligence. These language models can produce text that closely resembles human language and have been applied across a wide range of areas. Both tech giants and SaaS companies are competing to leverage LLMs' capabilities to develop smarter and more practical applications. However, the true potential of these AI systems is realised through seamless integration with other tools, plugins, and knowledge bases.
LLMs are excellent at providing answers to questions within their trained domains. However, they cannot address inquiries related to personal data, proprietary corporate documents, or content generated post-training. Imagine being able to engage in dialogues with our documents and extract responses using a large language model. This holds immense potential.
In this blog post, we will explore how open-source technologies like PGVector from Postgresql, Embeddings, Langchain and Ollama can be leveraged to perform advanced analytics on private company data while maintaining the highest standards of data privacy and security. We will also provide code examples and architecture diagrams to illustrate their usage.
Components:
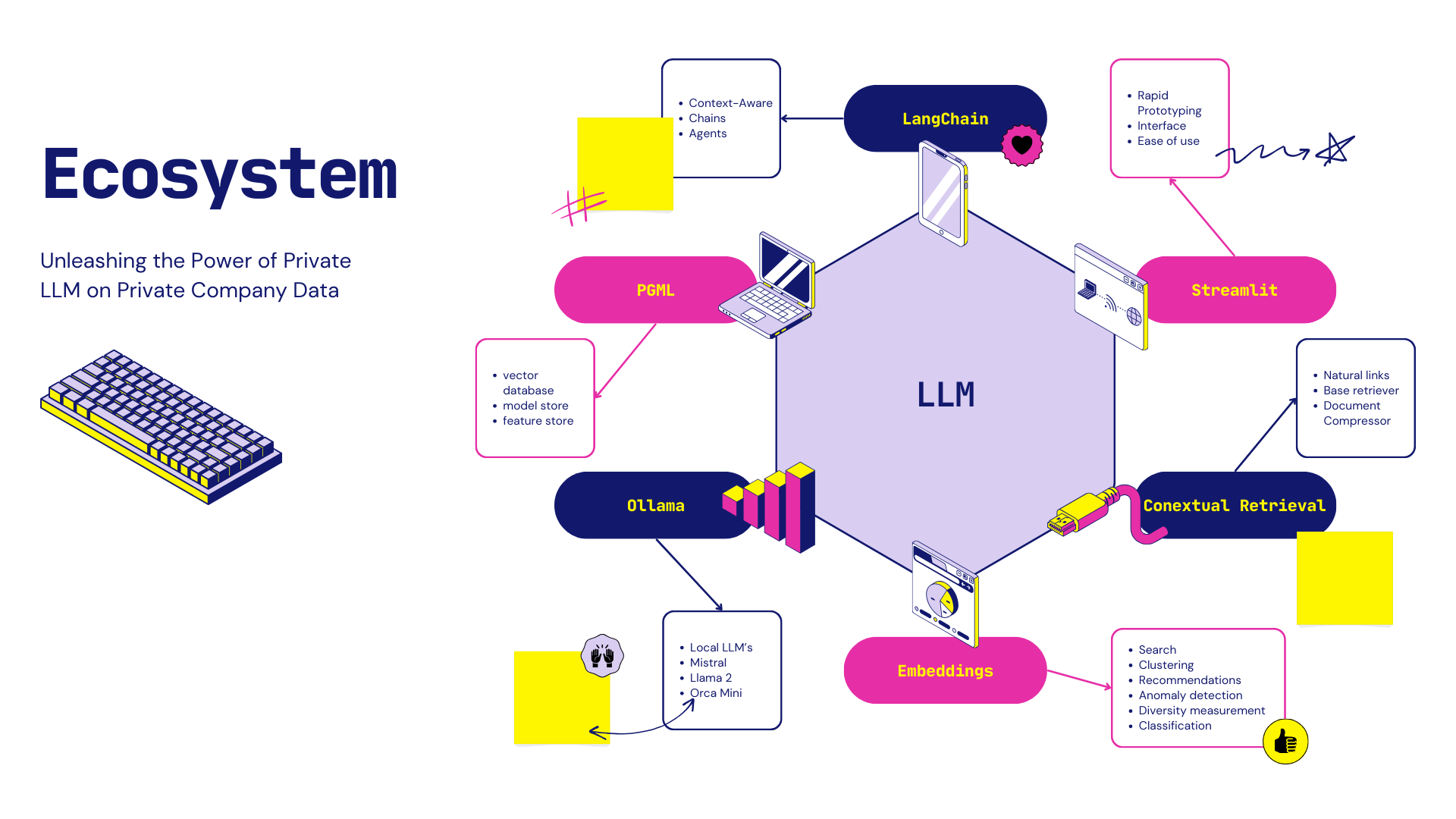
Intro to Langchain:
LangChain is an open-source developer framework for building LLM applications. In this article, we will focus on a specific use case of LangChain i.e. how to use LangChain to chat with own data. We will cover mostly the following topics in this article:
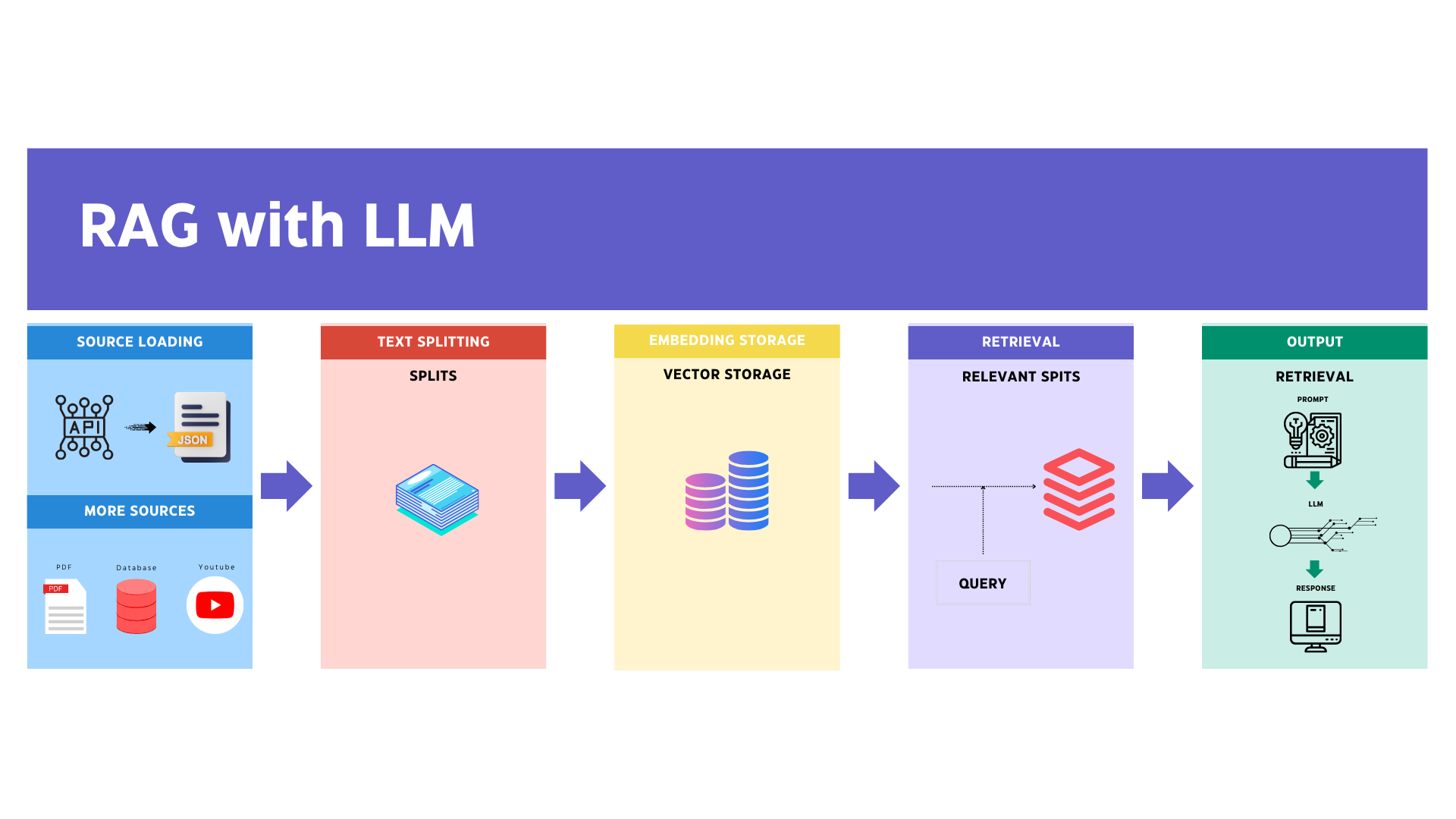
RAG process
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. RAG therefore helps improve the relevancy of responses by including pertinent information in the context, and also improves transparency by letting the LLM reference and cite source documents.
The steps involved in implementing RAG utilising Langchain are:
Source Loading:
To begin, the initial step involves loading our data. This unstructured data can originate from various sources, and you can utilise the LangChain integration hub to explore a comprehensive array of data loaders. Each loader is designed to return data in the form of a LangChain Document.
Text Splitting:
Following the loading process, text splitters are employed to divide Documents into segments of a specified size.
Vector Storage:
Subsequently, a storage system, often utilising a vector store (in our case, PGVector extension of Postgres), is utilised to both house and frequently embed these data segments.
Embeddings create a vector representation of a piece of text. This is useful because it means we can think about text in the vector space, and do things like semantic search where we look for pieces of text that are most similar in the vector space.
#numerical representation sample of Embeddings:[0.0053587136790156364,-0.0004999046213924885,0.038883671164512634,-0.003001077566295862,-0.00900818221271038]
Retrieval:
The application retrieves these data segments from storage, often selecting ones with embeddings similar to the input question.
Generation:
An LLM (Large Language Model) generates an answer using a prompt that incorporates both the question and the retrieved data.

Source — LangChain Docs
Coding Time (macOS)!
In this blog post, we will dive into a fascinating use case that involves harnessing the power of technology to enhance our company's CRM system related to opportunities and clients. Specifically, we will explore how we can leverage BigSpark's API to implement Retrieval Augmented Generation (RAG) using LangChain. By seamlessly integrating BigSpark's CRM API with , we aim to streamline our communication with various opportunities, ensuring a more efficient and data-driven approach to managing our client relationships using RAG with LLMs .
Step 1 : Getting Started
Langchain:
pip install langchain
Ollama:
Download and install Ollama from https://github.com/jmorganca/ollama for macOS or model serving.
In this blog we are going to use the smallest model to test available on Ollama that is orca-mini.
ollama pull orca-mini
Test orca mini on your Mac with test prompts.
ollama run orca-mini
Ollama should be now available http://localhost:11434
For Vector storage we can use Chroma DB other storage for storing embeddings and other releveant data like metadata. In this Blog we are going to focus on PGvector using PGML service https://postgresml.org/. Create and an account an we should be good to go.
Step 2:
This code block is used to send a GET request to the specified URL which is pointed to our internal CRM API "https://{rootUrl}/api/method/opps-notes".
url = "{rootURL}/api/method/opps-notes"payload = {}headers = {'Authorization': 'token yourTokenHere'}response = requests.request("GET", url, headers=headers, data=payload)
The response from the server is stored in the response variable. This response can then be processed further to extract the required information.
Response sample:
{"message": [{"opportunity_code": "CRM-OPP-xxx-xxxxx","amount": 1000000.0,"opportunity_name": "{Opportunity Name}","added_by": "hamza.niazi@bigspark.dev","added_on": "2023-10-10 12:33:42.968836","problem_statement": "The prospect of harnessing Databricks powerful platform alongside the advancements brought by Dolly V2 to develop a GenAI platform for large language models is undeniably exciting. Databricks' robust infrastructure and data processing capabilities can provide the scalability and performance needed to train and deploy such models efficiently. When coupled with Dolly V2's cutting-edge innovations in language modelling, we have the potential to create a revolutionary GenAI platform that not only pushes the boundaries of natural language understanding but also opens up a world of possibilities across industries, from enhanced chatbots to more intelligent data analytics. This collaboration could mark a significant leap forward in AI capabilities, enabling businesses to leverage the full potential of large language models for a wide range of applications.","sales_stage": "Initial Meeting","id": 53,"note_content": "Meeting with Databrick's Sales team."},...]}
Step 3:
Defining our loader:
We have overridden Langchain's JSONLoader as it only give use ability to load content from json files. We want the loading to be done directly from the HTTP request and fetching the reponse as object.
In JSONLoader we need to pass the json object instead of JSON file path for the loader to parse it correctly.
Modify your __init__ , load and parse method accordingly.
loader = JSONLoaderAPI(json_object = response.text,jq_schema='.message[]',content_key='note_content',metadata_func=metadata_func,)
Defining Text Splitter:
data = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)all_splits = text_splitter.split_documents(data)
Setting Unique ID's to avoid duplication:
ids = [(doc.metadata["id"]) for doc in all_splits]unique_ids = list(set(ids))
Initializing PGVector as vector store:
We will use GPT4AllEmbeddings for generating embeddings locally to be stored in PGVector
vectorstore = PGVector.from_documents(embedding=GPT4AllEmbeddings(),documents=all_splits,collection_name=COLLECTION_NAME,connection_string=CONNECTION_STRING,ids= unique_ids,pre_delete_collection = True)
Defining Template for queries:
template = """Summarize the main themes in these retrieved docs and add extra information from metadata:{context}Question: {question}Helpful Answer:"""QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)
Initialising Ollama supported by Langchain:
llm = Ollama(base_url="http://localhost:11434",model="orca-mini",verbose=True,callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]))
Defining our Contextual Retriever:
This code block defines a subclass of VectorStoreRetriever called ContextualRetriever, which is used to retrieve contextually relevant documents based on a query. We are formatting documents to to add metadata like Opportunity Name, opportunity_code, added_by, problem_statement, note content and amount in the context so our LLM's is able to get the additional data around opportunities.
# Define a class for ContextualRetriever that inherits VectorStoreRetrieverclass ContextualRetriever(VectorStoreRetriever):# Override the '_get_relevant_documents' methoddef _get_relevant_documents(self, query: str, *, run_manager):# Call the parent's '_get_relevant_documents' methoddocs = super()._get_relevant_documents(query, run_manager=run_manager)return [self.format_doc(doc) for doc in docs]# Method to format the documentdef format_doc(self, doc: Document) -> Document:# Format the page content of the documentdoc.page_content = f"Opportunity name: {doc.metadata['opportunity_name']}, opportunity code: {doc.metadata['opportunity_code']}, added by: {doc.metadata['added_by']}, added on: {doc.metadata['added_on']}, problem statement: {doc.metadata['problem_statement']}, note content {doc.page_content}, opportunity amount: {int(doc.metadata['amount']):d}, sales stage: {doc.metadata['sales_stage']}"return doc
Step 4: Applying RetrievalQA
This block of code is initialising a RetrievalQA object from a specific chain type. The from_chain_type method is a factory method that creates a new instance of the RetrievalQA class. This instance is configured with the provided llm (language learning model), and a ContextualRetriever object that uses the provided vector store for retrieving contextually relevant information.
# Create a RetrievalQA object from a chain typeqa_chain = RetrievalQA.from_chain_type(llm,retriever=ContextualRetriever(vectorstore=vectorstore),chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},chain_type="stuff",)
Let's try pulling everything together in Streamlit to see it in action:
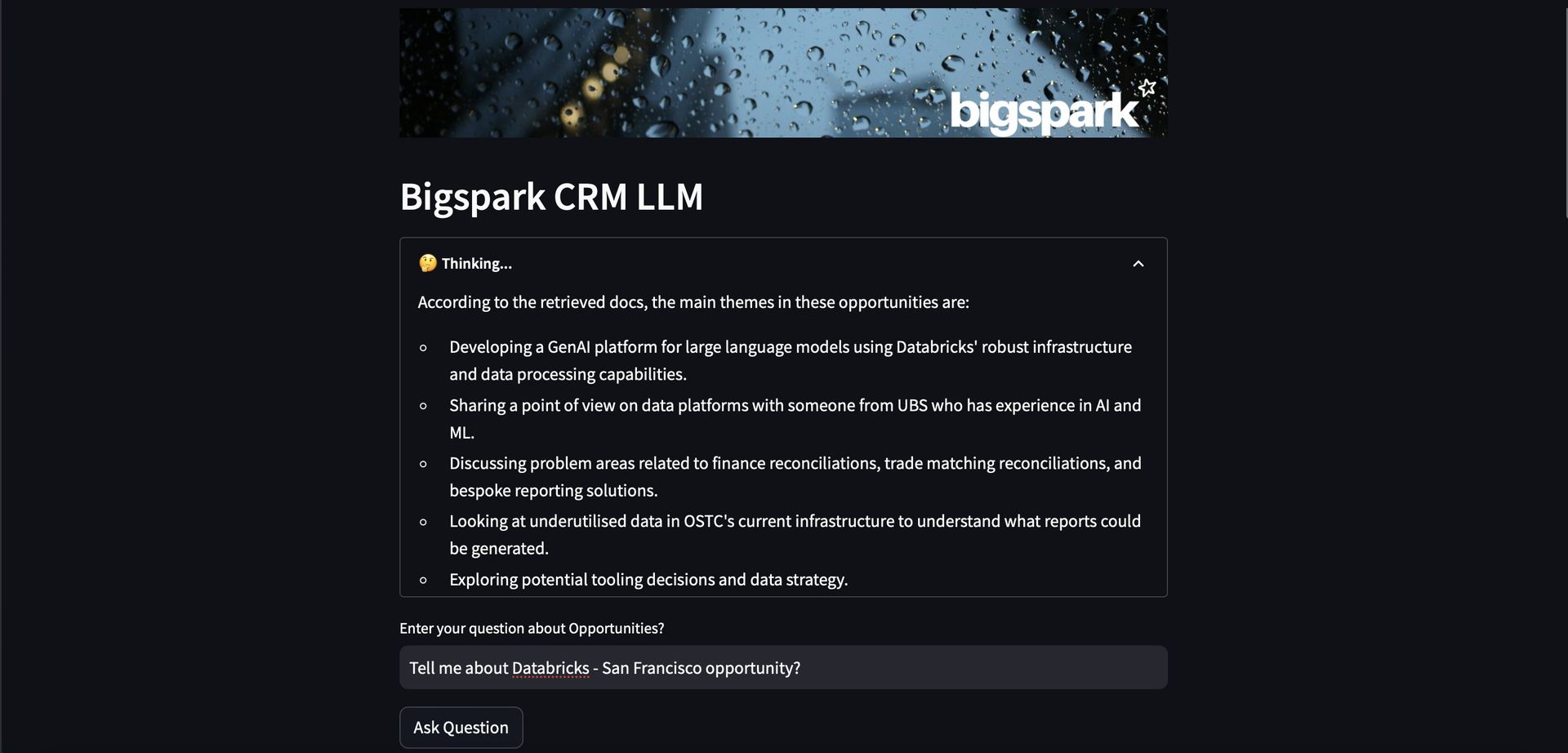
As a response, we get answers by using three retrieved documents through embeddings. In this context, we utilized a RAG (Retrieval-Augmented Generation) model to generate the answers. This model retrieves relevant information from a pool of documents and generates the answer based on that information.
Conclusion:
In this blog post, we have walked through the process of creating a single API QA app from scratch. We have covered the concepts of embeddings, vector stores, parameter tuning, chains, and vector store retrievers in detail. We hope that this article has provided a comprehensive understanding of these concepts to our readers. By following the steps outlined in this article, readers can create their own API QA app and customize it to suit their needs.
What's Next?
Moving forward, in the next part, we will explain how to create a Streamlit application with LangChain, a natural language processing library that helps in building conversational AI. We will also guide you through the process of deploying the model using Ollama on AWS, a cloud platform that provides scalable computing resources and storage. Finally, we will discuss the importance of adding memory to our conversation chains, which helps to provide a more personalised and relevant experience to users.
Hope that was useful.
No comments yet. Login to start a new discussion Start a new discussion